




Time
Optimization
Changing at fundamental level, the algorithm of some of the critical rules like constraints propagation, collapsing the project nodes early (analysis phase), minimizing the calls to hive meta store & other modifications, tremendously improve compile-time performance.

Advanced
Broadcast
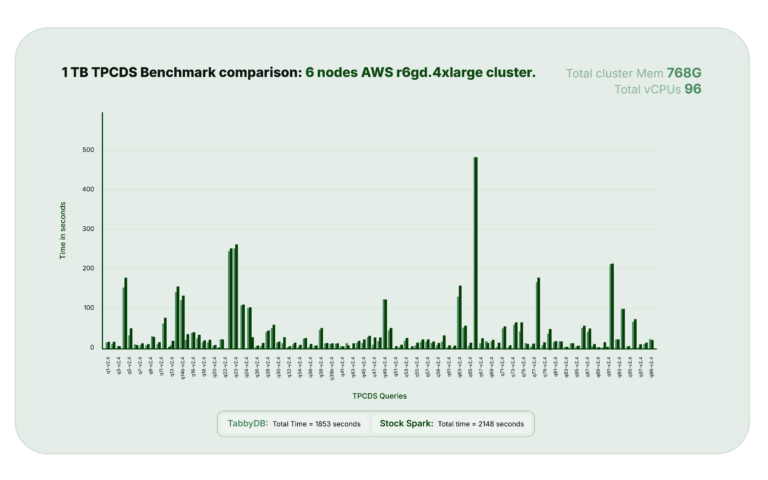
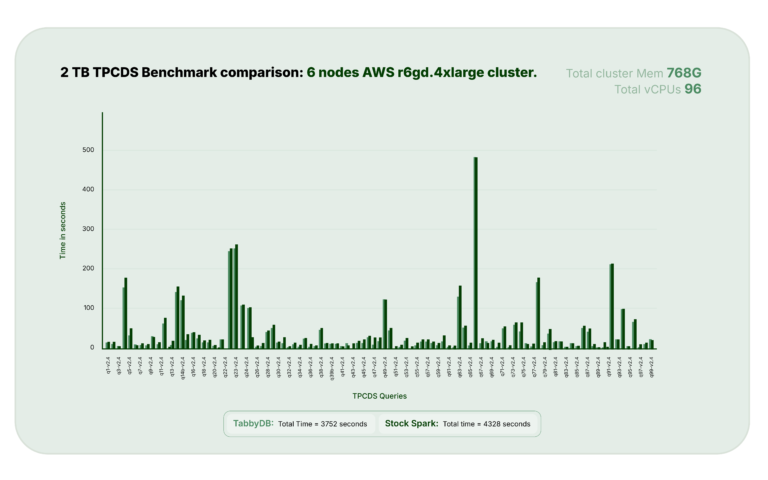
Our fork optimizes the broadcast hash joins on non partitioned columns, to do dynamic file pruning, boosting the runtime performance of nested join queries. In a limited TPCDS testing, it has shown 13% performance improvement in time taken, compared to stock spark.

Caches
Optimization
The cache lookup of in-memory plans is now more intelligent, improving the hit rate of successful lookups and reducing unnecessary computations. This heightened sensitivity can significantly enhance overall runtime performance and efficiency for complex queries.

Scalable
Query
The new rules & algorithm change allow for collapse of projects in the analysis phase, thereby capping the tree size. This results in savings in terms of time taken to compile, preventing out of memory errors.

Seamless
Integration
While boosting performance, KwikQuery's TabbyDB, retains full compatibility with Apache Spark’s APIs and features, allowing users to leverage familiar tools with enhanced speed.

System
Reliability
KwikQuery’s TabbyDB ensures consistent and reliable query execution, even under heavy workloads, while maintaining full Spark compatibility and minimizing unexpected failures.
